
The rapid evolution of generative artificial intelligence (GenAI) tools, which can produce various types of content including text, imagery, audio, and synthetic data, has ignited interest in the technologies’ vast potential to change the world of work. In order to quantify that potential impact and identify which work skills—and which jobs—are most exposed to potential change, Hiring Lab combined a host of proprietary job and skill data from Indeed with an assessment from GenAI of its own ability to perform certain tasks.
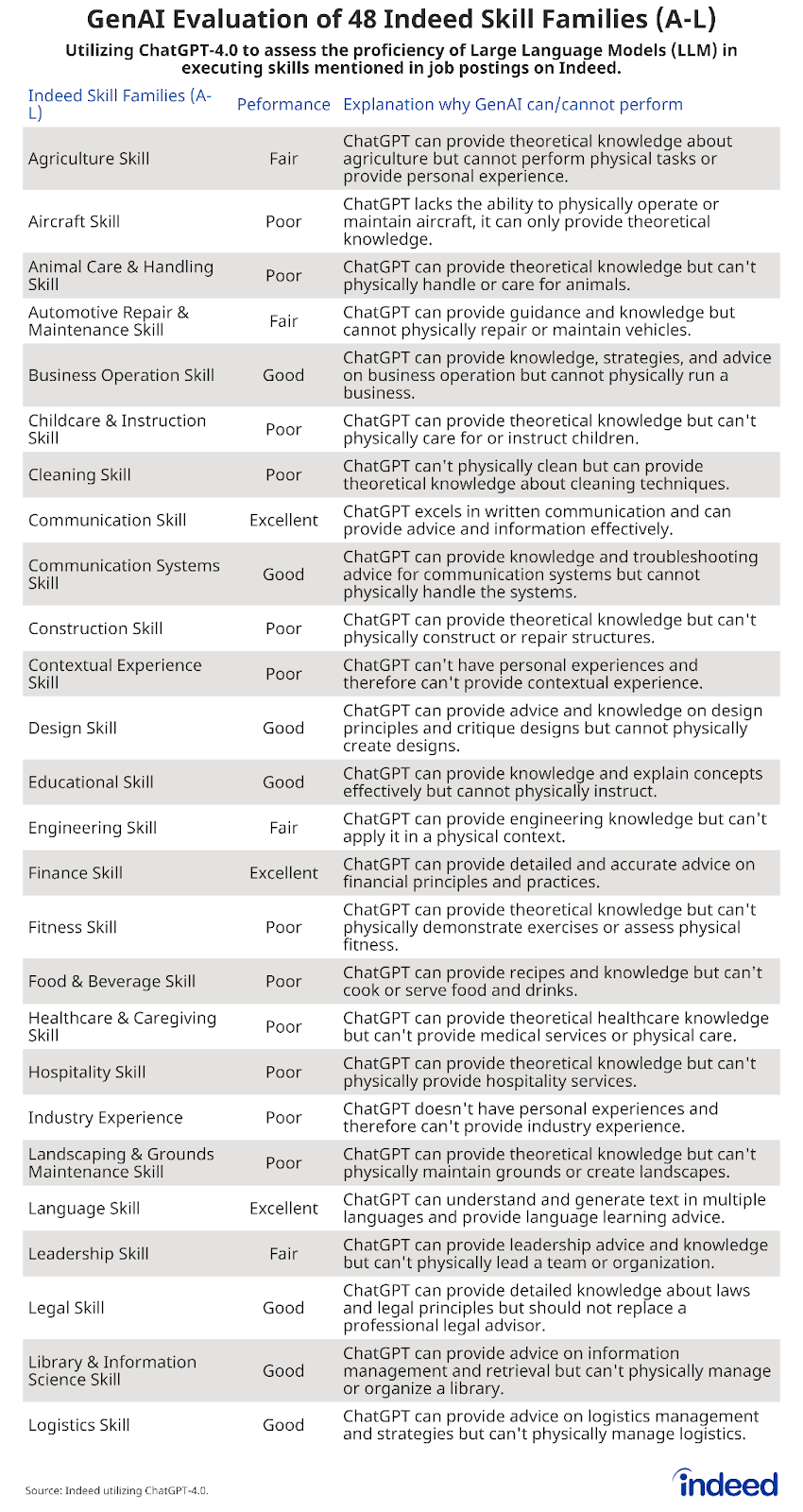
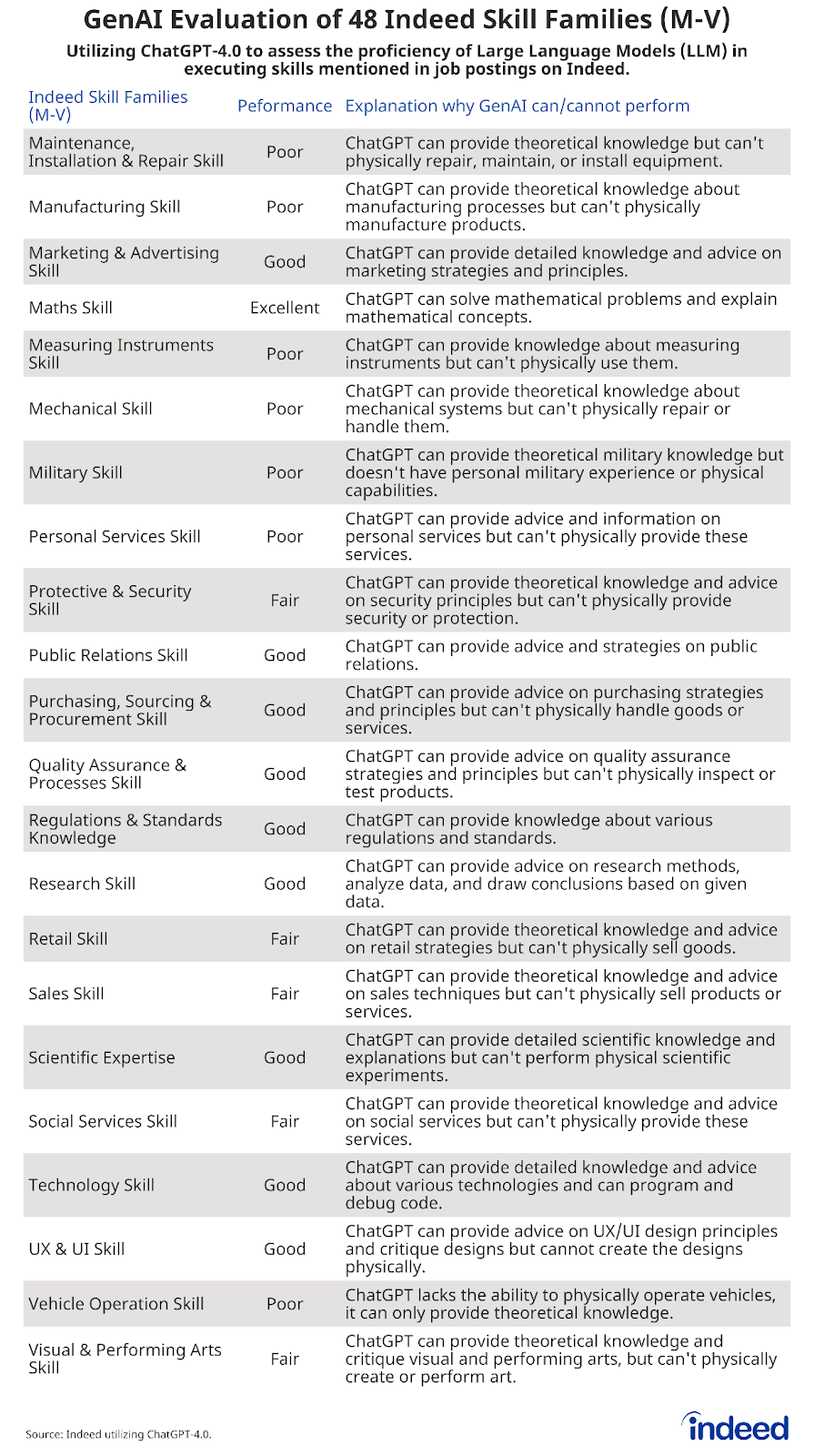
Starting with a universe of more than 55 million job postings mentioning at least one work skill published on Indeed in the United States over the past year, we identified more than 2,600 individual skills within those jobs and organized them into 48 skill families. We then asked ChatGPT-4.0, a leading GenAI tool, to rate its ability—either poor, fair, good, or excellent—to perform each skill family, with all skills within a given family assigned the same rating as the family overall.
For purposes of this analysis, “skills” refer to a worker’s abilities or proficiencies that are essential for carrying out job responsibilities and contributing to an organization’s success. Skills can encompass technical expertise, specific knowledge, and/or soft skills including communication, problem-solving, and leadership. This research focuses on critical skills alone and does not attempt to analyze essential licenses, certifications, and/or academic qualifications required of certain roles.
There are several reasons why we focus on skills alone:
- Licenses are legal permissions to perform specific activities, and certifications (and academic degrees) are formal recognitions of expertise or competence in a particular area. But they are not technically required to still possess a given skill, which is a specific ability or talent that may be able to be performed by a human or a machine.
- Required licenses and certifications vary widely from jurisdiction to jurisdiction, and are frequently updated or changed as new regulations are enacted or phased out. Similarly, certain employers may require certain qualifications for a given role—a PhD, for example—while others may not. Skills themselves largely do transfer equally across jurisdictions and preferences, and so were the main focus in our examination of which jobs (regardless of location or employer) will and won’t be exposed to change.
- GenAI technology may be able to support an individual while they study or prepare for a licensing or certification exam, but it cannot acquire or hold a license or certification itself; only a human can.
Data Sources
Four separate data sources were joined to create the final analysis:
- Indeed job posting data
- The base data for this analysis was drawn from more than 55 million US job postings published on Indeed between August 1, 2022, and July 31, 2023. Utilizing a full year of job postings helps to avoid potential seasonal bias in posting levels, types of jobs posted, etc.
- Work skills identified by Indeed
- Each of the 55 million+ postings included in the analysis mentioned at least one of more than 2,600 individual job skills previously identified by internal Indeed teams.
- The average job posting mentions 4 skills, with considerable variability across occupations: On average, software development job postings mention 12 skills; beauty and wellness occupations mention just 2 skills on average.
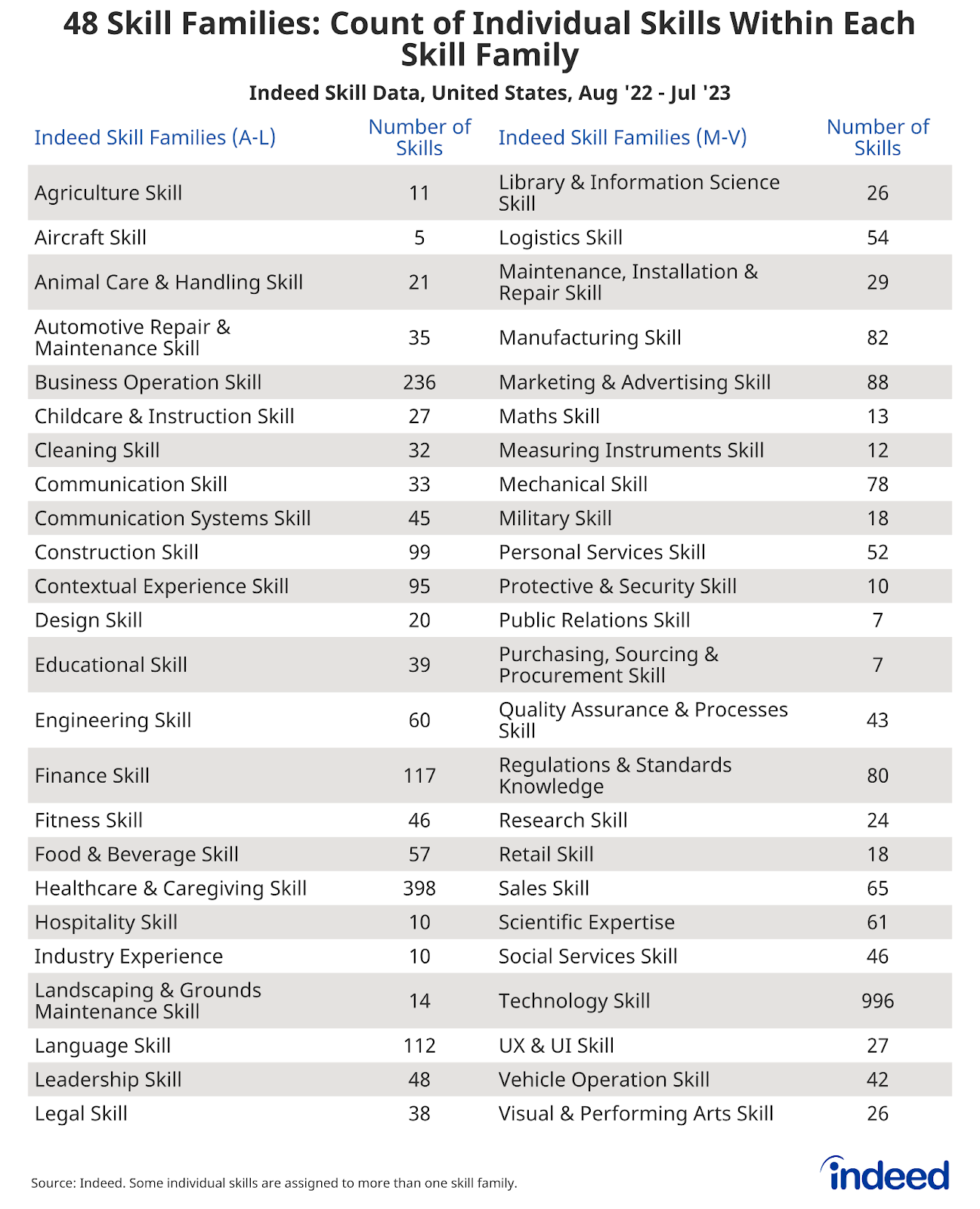
- The 2600+ identified skills were organized into 48 skill families by internal Indeed taxonomy teams, ranging from agriculture skills to visual & performing arts skills.
- Roughly ⅓ of skills appear in more than one skill family, and individual skills were weighted in the final analysis to account for this. For example, “Scrum” is a skill fundamental to the agile project management framework common at many firms. It is assigned to two skill families: Business Operation Skills and Technology Skills. “Scrum” receives a weight of 0.5 in each of the two skill groupings. If a skill appears in three groupings, it is given a weight of 0.33. And so on and so forth.
- Indeed Remote & Hybrid Job Tracker data
- Data from Indeed’s Remote & Hybrid Job Tracker, through July 2023, was used to evaluate the potential exposure to GenAI-driven change among jobs that are more easily or less easily done in a remote setting.
- GenAI’s evaluation of its own ability to perform identified skills
- Hiring Lab asked ChatGPT-4.0, a leading publicly available GenAI tool, to evaluate its own ability to perform the skills within each of the 48 skill families, from “poor” to “fair” to “good” to “excellent.” Each individual skill was assigned the same rating as the family overall. More details on this highly iterative process are below.
Measuring the exposure of jobs to GenAI
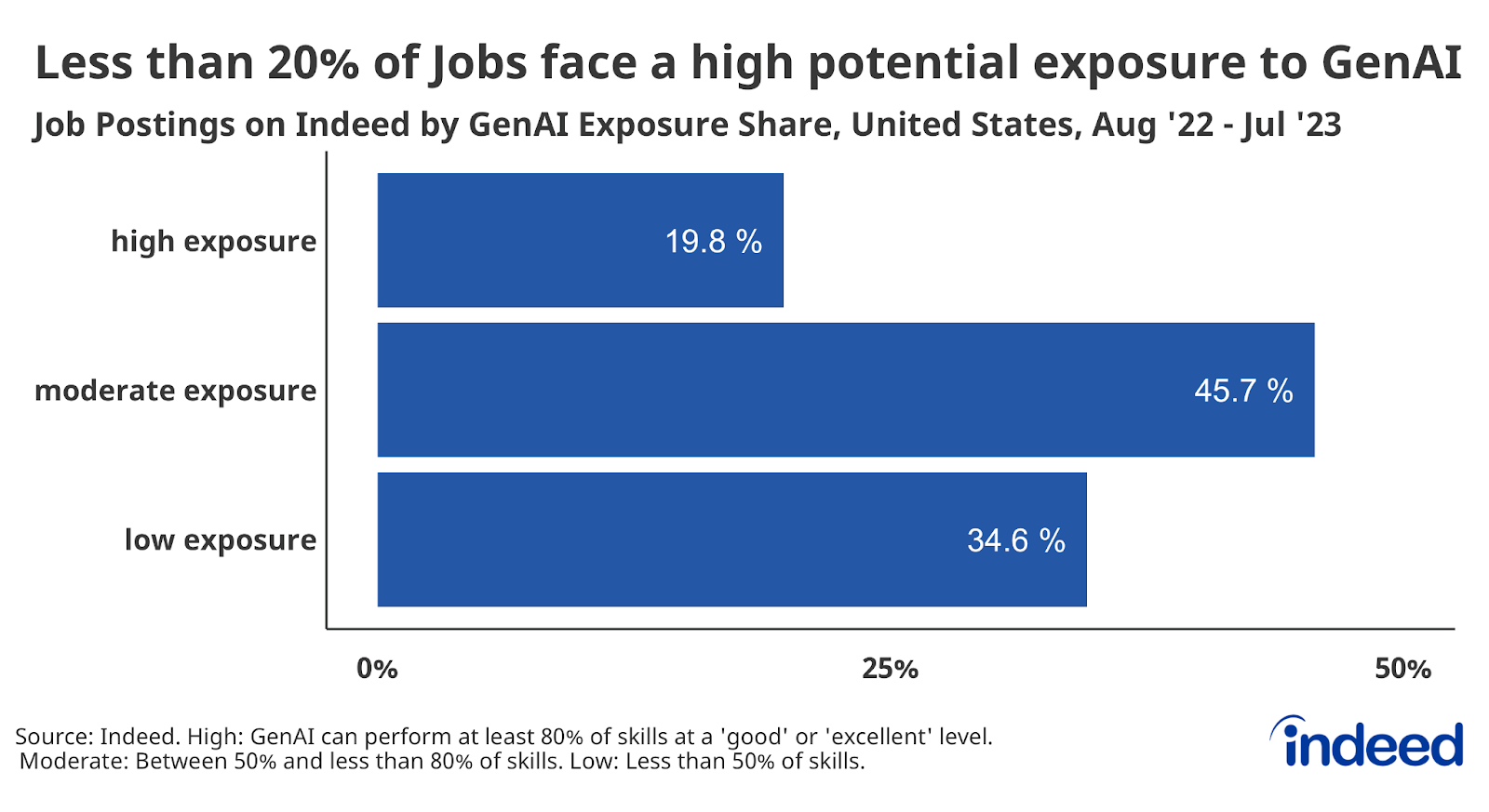
We calculated the share of skills by occupational group and occupations that fell into the four categories (poor, fair, good, excellent). GenAI’s impact was summarized into three exposure levels: low, moderate, and high, providing insights into its proficiency across various skills in the job market.
Jobs in which 80% or more skills can be done “good” or “excellent” by GenAI were determined to have the highest potential exposure to GenAI-driven change. Jobs in which between 50% and less than 80% of skills can be performed “good” or “excellent” were determined to have a moderate potential exposure to GenAI. Jobs in which less than half of skills could be done “good” or “excellent” were determined to have a low potential for exposure.
“Interviewing” GenAI
GenAI tools have access to enormous quantities of data and can process it incredibly quickly. Part of the fascination with GenAI tools built on large language models, like ChatGPT, is how advanced they have become at mimicking human language, responding to questions, and furnishing answers as a human would. Our iterative process in asking this tool to assess its own ability to perform work skills was comparable to conducting a series of interviews with a highly capable expert; one that talks like a human adult but is decidedly not human—and not always expert. Asking exactly the right questions, in exactly the right ways, was critical to generating results that hold up to human scrutiny.
Through many discussions with this “expert,” we often asked questions multiple times, tweaked formulations, and added more context for the large language model. Our first chat explored how to communicate with ChatGPT. Twenty iterations/interviews later, the questionnaire was finalized. The final chat with ChatGPT-4.0 prompts we used for our research can be found here.
As we got more familiar with ChatGPT’s style and quirks, our own ability to create the kinds of specific prompts required to generate the highly specific output we sought also grew. After feeding it data from the 48 identified skill groups, we sought to have the tool evaluate itself on a 4-point scale from poor to excellent at its ability to perform those skills, and why it rated itself that way.
Developing the performance rating scale was a lengthy process involving substantial experimentation. Initially, we began with a binary scale: 0 (cannot support) and 1 (can support). However, upon analyzing ChatGPT’s evaluation, it became evident that our more complicated research question—we didn’t only want to know if GenAI could or could not perform a skill, but also how well it could or could not do so—required more nuance. So we began exploring both 3-point and 5-point scales.
Survey questionnaires often employ a 5-point Likert scale, where the middle category (a rating of 3, on a 1-5 scale) is considered neutral. Similarly, a 3-point scale features a middle category (2) as neutral. When confronted with a similar 5- or 3-point scale, a human will often choose the neutral option as a proxy for “I don’t know,” or as a way to avoid having to take a more firmly “positive” or “negative” stance. After analyzing the explanations behind ChatGPT’s selection of the middle category, we concluded that providing a neutral option also gave GenAI an opportunity to avoid extremes, and we could not determine what a “neutral” impact might be in this context. We resolved to eliminate the neutral option, leading to the 4-point scale found in the final analysis.
Here is the prompt used to generate the specific file output based on that 4-point rating:

Minor tweaks in prompts made throughout the process resulted in significant differences and improvements in the quality and interpretability of the results received. For example, in our final “interview” we specifically asked the tool to “Please have in mind that these skills are needed in a job to perform a job.” Before adding this sentence, ChatGPT told us it was “good” at animal handling, cooking, and performing maintenance, installation & repair skills. After reading ChatGPT’s explanation for its ratings, however, we determined that it only said this because it was likely concluding it could help inform DIY enthusiasts or average consumers about these tasks, with no details on whether it could do these tasks professionally. Not unlike journalists who are trained to press when things don’t make sense and ask questions again when answers are unclear, we didn’t quite believe what we were hearing. And so we asked for more.
Here is the final output and ratings from our conversations with ChatGPT:
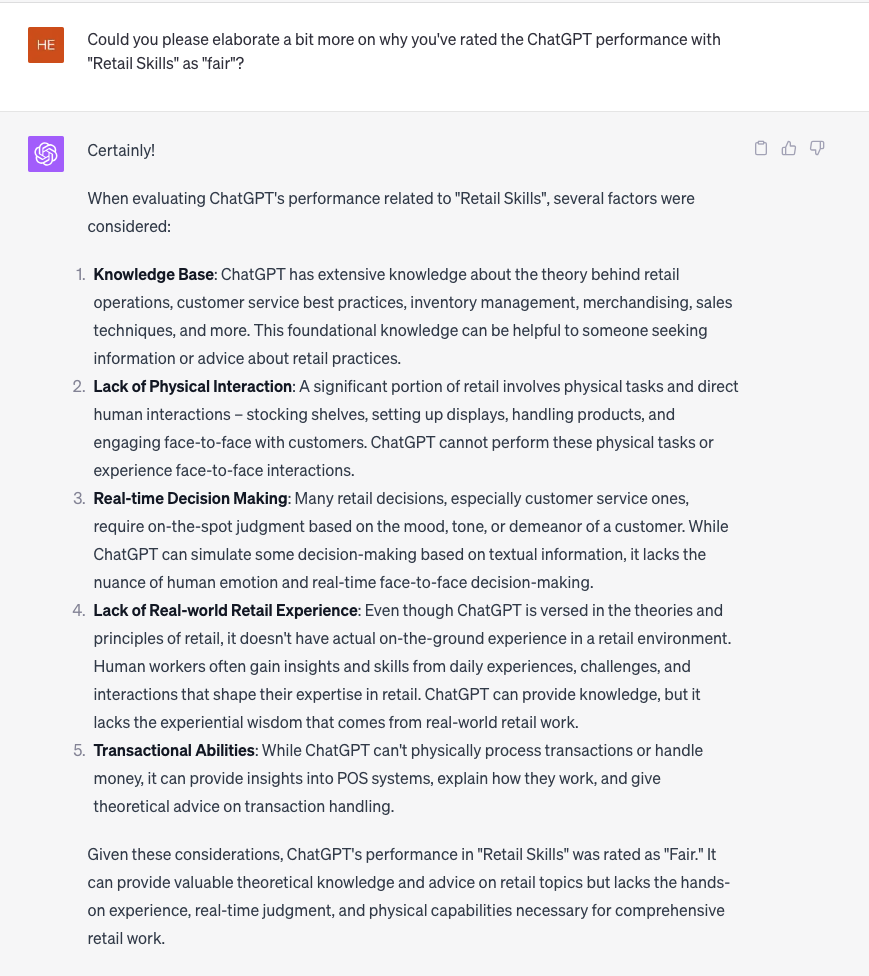
The final writeup focused on three occupational groups—driving, retail, and software development—as examples of jobs ChatGPT said it could perform relatively poorly, decently, and well, respectively. Our final step was to ask for a more precise explanation of ChatGPT’s assessment of the three skill families—“vehicle operation skills”, “retail skills” and “technology skills”—that play a crucial part for those three occupational groups. Below is its full explanation of its retail ability, for reference:
Robustness Checks
We reviewed our data against similar studies examining the abilities of artificial intelligence published by Pew Research Center and ILO, among others, and are confident our assessments are broadly consistent with other currently available research. And while we ultimately used Indeed’s own hybrid/remote tracker data to analyze the correlation between the ability to do a job remotely and its potential exposure to GenAI, we also asked ChatGPT to assess the importance of physical presence to its assessment. This additional rating served as a further robustness to better understand the performance evaluations.
We also conducted robustness checks using data from rejected candidates on the Indeed platform to evaluate the skills mentioned in job postings. Even when focusing on essential skills required by employers, the results did not reveal significant differences. We identified essential skills by accounting for how often employers requested a given skill for a certain job, taken from the job description itself. If employers mentioned certain skills more often in job postings for certain roles, then those skills were determined to be the most important ones.


